引言:当数据库遇见“无服务器”
在云原生技术浪潮的推动下,无服务器(Serverless)架构已从计算领域延伸至数据存储的核心——数据库。无服务器数据库服务,并非意味着数据库不需要服务器,而是指开发者无需再关心底层服务器的配置、扩容、维护与付费模式,能够按需使用、按量计费,并享受全托管的服务体验。它代表了数据库管理从“资产”到“效用”的根本性转变。
核心特征:解构无服务器数据库的本质
- 自动弹性伸缩:这是其最显著的特征。无论是应对突发流量高峰还是业务低谷,系统都能自动、即时地调整计算与存储资源,实现从零到峰值(Scale-to-Zero)的平滑过渡,用户只为实际消耗的资源付费。
- 全托管与运维自动化:服务商承担了硬件配置、软件打补丁、备份恢复、高可用部署与故障切换等全部运维重任。开发者得以从繁重的数据库管理工作中解放,专注于业务逻辑与数据价值挖掘。
- 基于消费的精细化计费:传统的预付费或按实例计费模式被颠覆。计费通常细分为计算单元(如请求数、查询时长)和存储量两部分,实现了成本与业务负载的精准对齐。
- 内置高可用与全球分发:服务通常默认提供跨可用区的数据冗余与故障自动转移能力,部分服务更支持低延迟的全球数据复制与本地读写,为全球化应用奠定基础。
主流服务形态与技术实现
目前,无服务器数据库服务主要呈现两种技术路径:
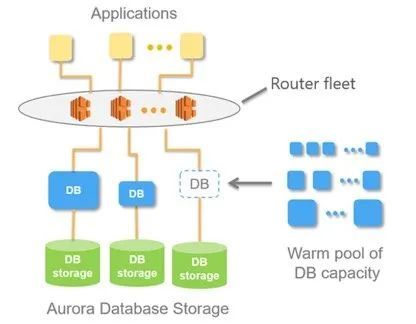
- 原生无服务器数据库:如Amazon Aurora Serverless、Google Cloud Spanner(提供了无服务器计费选项)、Azure Cosmos DB(无服务器模式)。它们从架构设计之初就为无服务器理念打造,在存储与计算深度解耦的基础上,实现毫秒级的独立伸缩。
- 基于现有服务的无服务器化接口:例如,通过HTTP API或GraphQL接口访问的数据库服务(如AWS AppSync配合DynamoDB、Firebase Realtime Database),它们将数据库操作抽象为API调用,后端资源完全由平台管理。
优势:为何选择无服务器数据库?
- 极致敏捷与降低认知负载:开发者无需成为数据库专家,即可快速构建和迭代应用,极大提升了开发效率。
- 优化的成本效益:对于流量波动大、间歇性运行或处于初期的应用,避免了资源闲置的浪费,总拥有成本(TCO)可能显著降低。
- 内置的企业级能力:安全合规、监控审计、备份加密等能力作为服务标准配置提供,降低了企业达成治理要求的门槛。
挑战与考量:并非万能钥匙
尽管前景广阔,无服务器数据库也带来新的权衡:
- 冷启动延迟:当从零扩展时,初始化新计算实例可能引入几十毫秒到数秒的额外延迟,这对极致延迟敏感的应用构成挑战。
- 成本预测复杂性:从固定成本到可变成本的转变,使得长期成本预测变得困难,需精细监控与分析用量。
- 功能与生态锁定:深度依赖云服务商特定的API、工具链和生态系统,迁移成本较高。
- 复杂查询与事务限制:部分服务可能对长时间运行的分析查询、复杂多表事务的支持不如传统数据库灵活。
适用场景与最佳实践
无服务器数据库特别适合以下场景:
- 流量模式不可预测的应用:如社交活动、电商促销、新功能发布。
- 开发与测试环境:按需使用,随用随停。
- 微服务与事件驱动架构:每个服务可拥有独立、轻量的数据存储。
- SaaS多租户应用:轻松实现租户间的资源隔离与弹性伸缩。
最佳实践建议:
- 从业务场景出发评估,而非盲目追求技术新颖。
- 设计应用时考虑无服务器特性,如采用事件驱动、幂等操作、优化连接管理。
- 实施细致的监控与告警,关注成本、性能与限制指标。
- 制定数据备份、归档与跨云/混合云策略,管理供应商锁定风险。
未来展望
随着边缘计算、人工智能与物联网的融合,无服务器数据库将向更智能的自治管理、更低延迟的边缘数据层、以及更统一的多模型数据体验演进。它将进一步成为构建现代化、响应式应用的默认数据基石。
###
无服务器数据库服务,是云计算将资源抽象推向极致的一个缩影。它通过将复杂性封装于平台之下,赋予开发者前所未有的敏捷性与自由度。选择它并非一个纯粹的技术决策,而应是一个结合业务目标、成本模型与架构哲学的综合性战略。理解其核心价值与固有约束,方能在这场数据管理的范式革命中,做出最明智的架构选择。