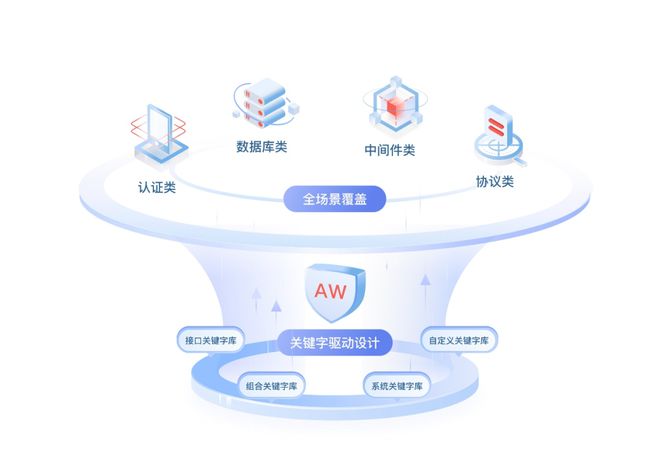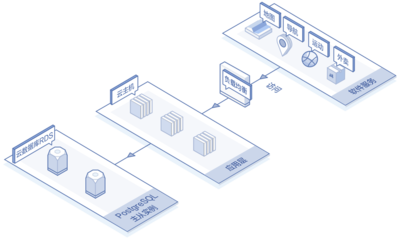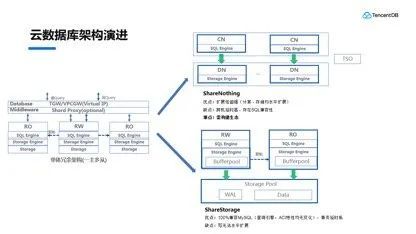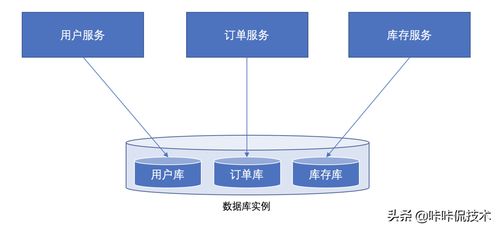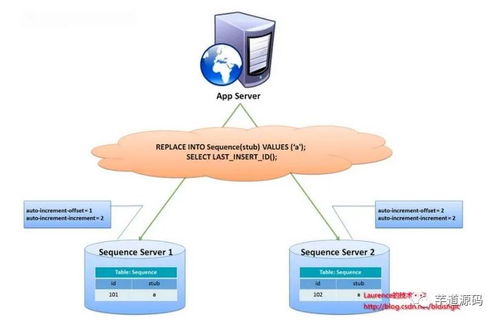
在数据库优化过程中,分库分表是常见的解决方案,用于应对数据量激增、读写性能瓶颈等问题。正如芋艿在CSDN博客中强调,盲目追求分库分表而不考虑实际需求,可能导致复杂度和成本上升,反而得不偿失。
分库分表的核心目的是解决数据库扩展性问题,但过早或过度拆分可能带来管理困难。例如,跨库查询、分布式事务处理会增加开发难度和维护成本。如果数据规模尚未达到分库分表的门槛,强行拆分只会让系统变得臃肿。
分库分表应基于业务场景进行决策。例如,高并发读写、海量数据存储的场景下,拆分是必要的;但对于小型应用,单库单表可能更高效。芋艿指出,开发者需评估数据增长趋势、访问模式和服务可用性,避免“为了分库分表而分库分表”的误区。
分库分表是工具而非目的。在数据库服务设计中,我们应优先优化索引、缓存和SQL语句,再根据实际压力逐步引入拆分策略。记住,技术服务于业务,理性选择才能实现长期稳定。